2009-03-14
八割の動詞
PC は忙しい時ほど壊れる. 先週は職場の PC にこの経験則が降りかかった. 頻繁にフリーズしはじめる VisualStudio 2008. VS 単体での修復では問題が直らず困り果て, 結局 OS から入れ直す羽目に. まあディスクが故障しなかっただけ幸いだと思おう...
OS の入れ直しは生活習慣を見直し悪習を捨てる機会でもある. 私の Windows 生活で最大の悪習は cygwin だ. ホスト OS への敬意を欠く cygwin には以前から後ろめたさを感じていたが, 惰性でずるずると使い続けていた. 今回のトラブルは良き市民たれという神(シアトル在住)の思し召しかもしれない. 啓示に耳を傾け, しばらく cygwin なしでがんばってみたい.
PowerShell

cygwin を捨てるということはシェルを乗り換えるということだ. いま Windows 民の間でホットなシェルは PowerShell らしい. まわりの Windows ファンは誰もが絶賛している. 私もこれを使ってみよう.
幸い, 私は良き Windows 市民でないのと同程度に良き UNIX 市民でもなかった. シェルやコンソールの設定はまったくカスタマイズしていないし, 書き溜めたシェルスクリプトもない. 主な懸念は何かにつけて使っていた GNU Make だけれど, これは scons で乗り切る目処がたった. (今のプロジェクトはバックエンドに python を使っているため, scons に対する市井の目はそれほど厳しくない.) 根無し草の引越しは気楽でいい.
新しい町での生活に向け, まず同僚から又借りしたガイドブック PowerShell イン アクション を読んでみる. この本はシェルというよりプログラミング言語の入門書として書かれている. 言語としての PowerShell も, これはこれで面白い. .NET 基盤の物量と UNIX 風シェルの流儀が LL の簡潔さで結びつけられ, 伝統的 Windows の億劫を償う小粋なツールに仕立てられている. ファンがいるのもわかる.
ただ言語として使う以前に, 日々のコマンドをどう入力すればいいのか, 要するに ls や rm や find や grep や start みたいな真似をどうやるか, そういうシェルの基本がよくわからない. いまいち敷居が高い. そこで "イン アクション" は中断し, Windows PoerShell クックブック に浮気. 気をとりなおし読み進めると, こっちには私の知りたいことが書いてあった. 言語としての話は天下り的でおざなりだけれど, シェルの入門編はこんなもので良い気がする. (どうせ sh の文法だって未だによくわかってないんだから...) どちらの本もぱっと見は分厚い. でも後半はシステム管理者として Windows の構成を自動化する話ばかりだから, 初心者プログラマがシェルとしてとして使うのなら前半だけ読めばいいだろう. 私もまだ半分しか読んでない.
それでも実物を触りながら読み進めるうちに PowerShell の上でもなんとか暮らしていけそうな自信も湧いて, 月曜からの Windows 生活がちょっと楽しみになった.
Verb-Noun naming
PowerShell の特徴のひとつに, Verb-Noun 命名規則がある. "Get-Command" や "Select-Object" というように, PowerShell のコマンドはすべて <動詞-名刺> スタイルの名前を持つ. (もちろん頻出コマンドには alias がある.) 規約を決めるだけでなく, 動詞の種類を絞ることでコマンド名を憶測しやすく保っている. 動詞や名詞をキーにコマンドを検索するなど, この規約を前提とした支援機能もある.
クックブックによれば, PowerShell は 50 未満の動詞によってシステムの 80% の管理を可能にする のが目標なんだとか. 本の付録にもその動詞リストがついてくるし, 同じものが MSDN にもある. (というかこっちがオフィシャル.) Add, Clear, Copy, Get, ... リストには見なれた動詞が並んでいる. New や Out なんかは動詞じゃないけれど, PowerShell ではアクションを示す単語を一律 Verb と呼ぶ.
REST が示したように, 選びぬいた動詞だけを使うことでソフトウェアは単純になる. PowerShell の 50 種類(実際は 64 種類)は HTTP のメソッドと比べてだいぶ多いけれど, それでも厳選しただけあってよく使う動詞は網羅されている気がする. 先の動詞表には(一貫性のために使うべきでない)主要動詞の類義語もいつくか併記されている. 主要動詞と類義語はあわせて 186 種類. これだけあれば Windows の管理作業に限らず普段書くコードの動詞も事足りる... なんて上手い話はないだろうか. 世の中のコードはどれだけの動詞を使いこなしているのだろう.
動詞を数える
実際に数えてみよう. とりあえずそこそこの規模があり, かつ動詞を数えやすそうな Java を相手にしてみる. Sun Java の標準ライブラリは rt.jar というランタイムにまとめられている. こいつの中身を数えよう.
メソッド呼び出しの列挙
まず各クラスのバイトコードを読んで, INVOKEVIRTUAL などメソッド呼び出し命令から呼び出されるメソッド名を列挙する. メソッド定義でなく呼び出しを数えるのは利用頻度を知りたいから.
... get_id write_repositoryId updateIndirectionTable start_block marshal write_value end_block writeEndTag getORBData useRepId getClass getCodebase writeValueTag getORBData useRepId get_id write_repositoryId updateIndirectionTable write_value writeEndTag start_block position ...
動詞の切り出しとフィルタ
次にこのメソッド名から動詞を切り出す. Java のメソッド名はふつう動詞が先頭にくる. だから先頭が動詞の camelCase を仮定し, /^[a-z]+/ みたいな 正規表現で先頭語を切り出すことができるだろう. たとえば 'writeValueTag' なら 'write' が切り出される.
切り出した単語は WordNet の動詞目録 (一万語) と 照らしあわせ, 動詞が否かを判定する. (Stemmer での正規化くらいはやっておいた. ほとんどみな原形だから大差はなかったけど.)
そのほか getXxx() や isXxx(), setXxx() は JavaBeans プロパティへのアセクセスとみなし, 動詞には数えない. 同様に equals() と toString(), hashCode() も ほとんど演算子みたいなものなのでカウントからは外しておく. こんな風にいらないものを除けたうえで, 最後に残った動詞毎に出現頻度を数えた.
rt.jar の動詞
rt.jar には約 56 万箇所のメソッド呼び出しがあり, うち動詞に該当するのは 23 万箇所. その中でおよそ 800 種類 の動詞が使われていた. トップ 20 はこんなかんじ:
単語 頻度 append 48374 add 11626 put 10867 decode 10319 write 7422 get 6746 access 6497 create 6419 read 6098 value 4416 size 3729 remove 3373 fill 3098 check 2975 draw 2807 do 2403 char 2363 print 2170 close 1983 paint 1950
get は getXxx() でなく get() に由来するもの. value はきっと動詞の意味では使ってないけれど, "大切にする" という動詞でもあるためカウントされている. size や char も同様. いちいち弾くと大変なので放ってある. あとはまあ, そんなものかという感じだと思う. append が突出しているのは文字列連結だろうか. 完全なリストは gist した.
さて, PowerShell の標準動詞 65 語はどれだけ JDK のメソッド動詞を網羅しているだろう. 集計してみると, 頻度で重み付けをした網羅率は 23% だった. 800 語からランダムに 50 語選ぶとせいぜい 50/800 = 6% だから, それよりは良い. けれど目標の 8 割は遠そうだ.
JDK の語彙は PowerShell のように統制されていないから, 似たようで違う語もばんばん使われている. そこで PowerShell 動詞の類義語も含めた 186 語を使い集計しなおすと, 重みつき網羅率は 60% まで上がった. これもランダムの値 (22%) よりはマシだけれど, いまいちぱっとしない.
Zipf の法則

そもそもの疑問: Windows の管理ならともかく, JDK のような巨大ライブラリの 8 割をたった 50 個の動詞でカバーできるのだろうか.
答え: できる. JDK のメソッド呼び出し動詞リストを足し合せていくと, 全 800 語の中から頻度順に 53 語あれば 80% の呼び出しをカバーできる. 107 語あれば 90% に届く.
上手くいくのは, 多くの言語がもつある性質のおかげだ. Wikipedia によると, <サイズが k 番目に大きい要素の全体に占める割合が 1 / k に比例する> ような分布を "Zipf 分布" という. 適当な文書中の単語の登場頻度が Zipf 分布をとる経験則はよく知られている. 私はむかし 新ネットワーク思考 を読んで知った.
JDK 動詞の頻度も, (厳密な Zipf 分布かはともかく)ある種の指数分布に従っている:
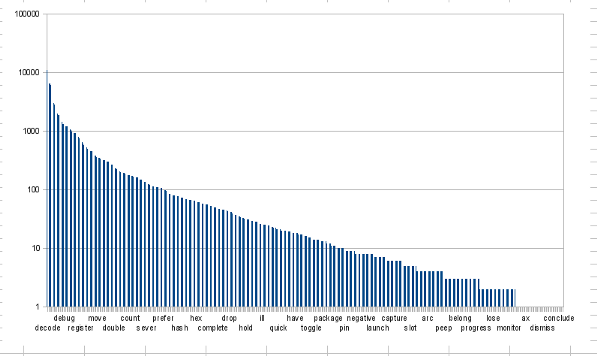
こうした分布ではわずかなトップ項目が大多数を占める性質をもつため, 50 語が 80% を占めても不思議はない. 網羅率の累積度数グラフはこんなかんじになる:
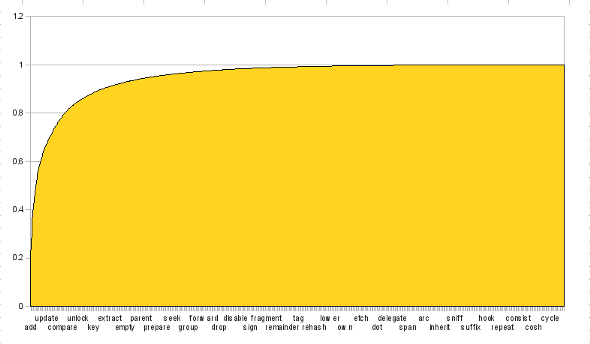
Java の語彙
PoweShell の動詞がいまいち低い網羅率だったのは, 想定している語彙の母集合が異なるからだろう. つまりプログラミング言語という小さな分野でも, 対象によって語彙の集合や分布にはばらつきがあるようだ.
ただ, それだと私の密かな野望 ("Java プログラマのための英語入門" や "速読 Java 単語" を出版してゲットリッチ) が 危機に晒されてしまう. 困る. 多様性が善とはいえ, Java の中くらいは Newspeak であってほしい. 実際のところはどうなのか, PowerShell 云々以前に Java プログラム間の語彙のばらつきを調べておきたい. JDK を基準に他のコードベースもあたってみることにしよう.
Ant
といっても私はそんなに Java のライブラリを知らないのでした... 古株メジャーどころを中心にいきます. まず ant (ant.jar):
- 動詞数: 215 語
- 総頻度: 12137 回
- 八割で: 22 語
- JDK 網羅率( 50 語): 83%
- JDK 網羅率(100 語): 91%
JDK 網羅率は, 先に示した JDK 動詞のトップ N 語が Ant の動詞をカバーする割合を呼び出し頻度で重みづけをして求めたもの. JDK 自体での網羅率が 50 語と 100 語 それぞれで 8 割と 9 割だったことを考えると, 上の結果は悪くない. むしろ JDK よりちょっといい. 相対的に語彙が乏しいのだろう.
トップ20は以下のとおり:
append 4456 add 977 log 717 create 535 size 389 close 351 access 334 write 215 read 195 get 178 class 159 put 159 exist 145 print 133 index 126 replace 120 start 103 check 99 remove 98 equal 92
log, index, start あたりに Ant っぽさを感じなくもない.
Tomcat
つぎは servlet container の Tomcat. (catalina*.jar, jasper*.jar):
- 動詞数: 362 語
- 総頻度: 39324 回
- 八割で: 43 語
- JDK 網羅率( 50 語): 69%
- JDK 網羅率(100 語): 78%
Ant より少し大きい. そしてがくっと網羅率が落ちた. ゲットリッチが遠のく...
トップ 20:
append 10954 add 1882 put 1339 generate 1257 print 1010 write 761 get 694 debug 651 find 623 remove 601 short 552 create 532 close 530 handle 518 consume 502 parse 476 value 465 push 455 fill 410 char 410
parse generate, write あたりに JSP の気配.
Hibernate
O/R Mapper の Hibernate (hibernate3.jar) はどうか:
- 動詞数: 288 語
- 総頻度: 23624 回
- 八割で: 34 語
- JDK 網羅率( 50 語): 70%
- JDK 網羅率(100 語): 84%
語彙数は Ant と Tomcat の中間くらい. JDK 網羅率も Ant と Tomcat の間. 規模と網羅率は相関するのかな?
トップ 20:
append 6492 add 1995 register 1444 put 1036 get 749 class 622 create 608 size 486 read 450 match 414 debug 357 trace 306 attribute 278 access 270 close 242 load 239 visit 227 write 212 remove 210 parse 207
visit が 220 回というあたりにくわばら感をおぼえます.
Eclipse
一説によれば 一千万行を越えたという Eclipse (plugins/*.jar) に挑戦. 網羅率と規模に相関があるならでかいコードは絶望的なはず:
- 動詞数: 836 語
- 総頻度: 366722 回
- 八割で: 58 語
- JDK 網羅率( 50 語): 69%
- JDK 網羅率(100 語): 80%
良くはないけれど, 規模を考えると下げ止まった感もある. トップ 20:
append 45202 add 35877 create 20058 access 18282 get 11286 size 10215 put 10051 remove 9480 value 6575 update 5734 log 5148 find 4904 write 4793 check 4685 print 4426 close 4204 handle 4088 dispose 3909 bind 3604 contain 3541
SWT の仕業で dispose がランクイン. bind はなんだろう.
S2Container
こんどは小さい方に倒してみた. DI Container の Seasar2 (s2-framework.jar):
- 動詞数: 153 語
- 総頻度: 5571 回
- 八割で: 30 語
- JDK 網羅率( 50 語): 70%
- JDK 網羅率(100 語): 85%
あらら. Hibenate より網羅率が低い. 規模だけの問題でもなさそう.
トップ 20:
append 1129 add 397 class 373 get 280 create 270 put 211 assert 197 register 174 size 134 close 96 write 87 wrap 84 convert 80 remove 77 execute 76 access 66 contain 63 set 61 read 61 clear 60
類似プロジェクト
規模のインパクトはありそうだが, それだけでもない様子がわかった. それなら今度は似たジャンル同士を比べてみよう. いくつかの HTTP サーバについて網羅率を求める. 相関を見るために, JDK 網羅率だけでなく Tomcat 網羅率も計算してみた.
jetty: (183 語)
- JDK 網羅率 (50 語): 76%
- Tomcat 網羅率 (50 語):74%
grizzly(196 語)
- JDK 網羅率 (50 語): 72%
- Tomcat 網羅率 (50 語): 68%
opengse(308 語):
- JDK 網羅率 (50 語): 80%
- Tomcat 網羅率 (50 語): 79%
あらら. おしなべて Tomcat 網羅率の方が低い. 小手先の類似より大数の法則の効き目が大きいというかことなあ.
こんなしょぼい工夫だけだと, 今より汎用的かつ網羅率の高い動詞集合を求めるのは難しそうだ. とはいえ巨大な Eclipse 相手でも既に 100 語で 80% は網羅できている. Java のコード相手なら JDK のトップ 100 語は悪くない. 妥協のラインには届いた. "Java プログラマのための英語入門" のオビは <Java(tm) の巨大なクラスを徹底分析! この 100 語を覚えれば, どんなソースコードも八割はすんなり頭にはいる!> なんてかんじに煽ればよかろう.
定義の頻度分布
著しい皮算用に一通り盛り上ったところで現実に帰る.
我が身を振り返ると, 私が動詞に悩むのはメソッドを呼び出す時よりそれを定義するときだ. もともと PowerShell 標準動詞の網羅率を試す目的があったから, これまでの集計ではメソッド呼び出しの回数で重みづけをしてきた. けれど下心に引きずられて道が逸れていた今となっては 呼び出し回数より定義の回数を数えた方が意味ある指標にならないか. それに "Java プログラマのための英語入門: API 徹底活用編" よりは, "間違いだらけのメソッド名" の方が売れ筋のにおいがするでしょ.
そもそもこの二つの分布はどれくらい違うのだろう. ふたたび JDK の rt.jar で数えてみたところ, メソッド定義は 58444 回あり, 動詞は 830 種類. 動詞の数は呼び出し時と大差ない. けれど分布はけっこう違う.
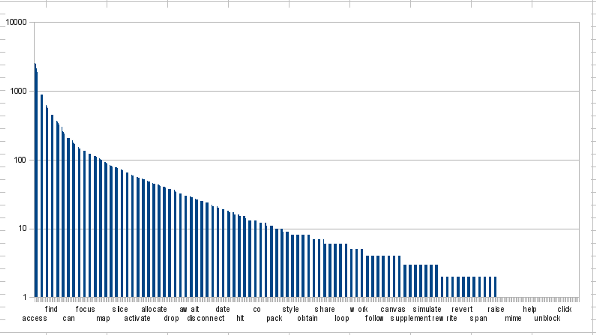
グラフじゃ単語が見えないですね...トップ 20:
create 3544 ( 8 -> 1) access 2877 ( 7 -> 2) add 2544 ( 2 -> 3) write 2452 ( 5 -> 4) read 2087 ( 9 -> 5) paint 1883 ( 20 -> 6) remove 1634 ( 12 -> 7) run 1278 (101 -> 8) update 1113 ( 26 -> 9) decode 1094 ( 04 -> 10) put 927 ( 03 -> 11) check 883 ( 14 -> 12) insert 877 ( 46 -> 13) parse 873 ( 22 -> 14) start 843 ( 21 -> 15) end 735 ( 34 -> 16) get 707 ( 06 -> 17) visit 670 ( 48 -> 18) print 635 ( 18 -> 19) handle 612 ( 32 -> 20)
ためしに(呼び出し頻度を使った) JDK 網羅率を計算すると 50 語で 61%, 100 語で 74% しかない. 頻繁に定義されるメソッドの動詞と頻繁に呼び出されるメソッドの動詞は必ずしも一致しないようだ.
各語の右には順位の変動を示した. 順位の変動が大きな動詞もあれば, あまり動かない動詞もある. 違いは何だろう. 呼び出し回数と定義回数で順位が違うものを順に並べてみる:
定義回数の方が多い動詞トップ10:
run 1.19 mouse 0.3 action 0.23 support 0.15 accept 0.14 extract 0.11 finalize 0.08 slice 0.07 focus 0.06 instantiate 0.05 operate 0.05
呼び出し回数の方が多い動詞トップ 10:
append -59.78 put -12.34 decode -11.53 add -11.41 get -7.33 write -6.28 value -5.13 read -5.07 access -4.62 size -4.33 create -3.72
右の数字は正規化した重みの差を表している.
呼び出し回数が多いのはわかりやすい. よく使われる(具象)クラスのメソッド, たとえば StringBuider#append() や各種コレクション の size(), get(), put() だろうとあたりがつく.
定義回数が多いのも想像はできる. Runnable#run(), なんとか Listener の actionPerformed(), Visitor 類の accept(), GC から呼ばれる finalize() (使うなと言ってるくせに...), など, よく使われるコールバックの定義に違いない.
簡潔な文法を好む言語だと, 前者は組込み演算子の類に短絡され, 後者は無名関数やコードブロックの一味にまとめられている. Java にしたってコールバックメソッドはインターフェイスで定義された名前をつければ済む. 簡潔ではないにしろ動詞を捻りだす苦労は少ない.
とはいえ上に示した定義頻度グラフのカーブでは, 概形が指数分布なのに一番左寄りの高頻度部は対数軸表示でも直線にならず急騰している. これを見るとコールバックの定義は無名関数など言語で支援しがいのあるものに思えてくる.
いずれにせよ頻繁に定義するものの多くは動詞云々以前に名前を付けずに済むのが一番ラクで, 実際そうなっている. それ以外の, 定義する頻度が多く利用頻度も多いものは, 利用頻度順に選り分けた語彙を参考にすればいい. つまり "速読 Java 単語 100" はいけそうだけれど, "間違いだらけのメソッド名" は企画倒れってことだなあ. 残念...
まとめ
PowerShell の話をするつもりが金稼ぎの企みに脱線しました. 脱線後のまとめ:
- Java のメソッド呼び出しに登場する動詞は JDK/JRE の rt.jar 内で およそ 800 種類
- 動詞の登場頻度は Zipf 分布かもしれない指数分布に従う.
- JDK の頻出動詞トップ 100 語で代表的なオープンソースプロジェクトの登場動詞を 80% くらいカバーできそう
- プログラムの対象分野による語彙の偏りは HTTP サーバについては見つからなかった
- 単なる統計リテラシ不足かも
- メソッド呼び出しでの動詞登場頻度とメソッド定義での動詞登場頻度は一致しない
- 呼び出し頻度が多いのは, 文字列やコレクションなどよく使うクラスのもの
- 定義頻度が多いのはリスナやスレッドなどのコールバック
- "間違いだらけのメソッド名" は売れない気がした
- "Java プログラマのための英語入門: API 徹底活用編" にはまだ希望が...
- オビだけ考えた
- 実験コード(未整理)
調べれば面白そうだけど挫けたこと:
- より多くのプロジェクトの集計
- 他の言語の集計
- 名詞や形容詞の集計
- よりハイテクな統計技法の活用
- 誰かやってくれー
- OOPSLA あたりでやってる人はいないのかしら
おまけ
実は動詞じゃなかった単語たち(WordNet しらべ):
- shutdown, cleanup, lookup, wakeup, backup
- concat, eval, dup, init
- unmarshal, unread, rewind
- layout, plus
- mkdir, gc