2011-04-26
Clang のコード補完
Clang のツリーを眺めていたら, "clang-completion-mode.el" というファイルがあった. clang のプログラムを呼び出してコード補完ができるらしい. (使いかたを説明してくれている人もいた.) 以前読んだ時 は気付かなかったけど, 二年前からあったようだ. こんなものがプラグインで書けてしまうなんてさすがモダンなコンパイラは違うなーインデクスはどうするのかなーと 感心しつつコードを見ていたらインデクスのような前処理はないようす. それに全然プラグインじゃない. Clang 組み込みの機能として実装されていた.
以前から Xcode(4) がどんな風に Clang を統合するのか気になっていた. コード補完はそうした取り組みの一環かもしれない. 高々 Emacs のため Clang 組込みの機能を増やすとも思えないからね.
というわけでざっとコードを眺めてみよう.
Clang 概観
まず簡単に復習を. よくあるコンパイラと同じく, Clang のコードも字句解析, 構文解析, 意味解析, コード生成といったモジュールにわかれている. 各モジュールはサブディレクトリにまとめられており, 字句解析をするのは Lex モジュール, 構文解析が Parse, 意味解析が Sema, コード生成が CodeGen といったかんじ. 各モジュールを協調させる mediator の Frontend と Frontend をラップして CLI を提供する Driver が全体の上に乗る.
Parse と Sema の関係は, Parse が Yacc などで自動生成されるコード相当, Sema は semantic action として手書きするコードにあたる. コンパイラの各フェーズを受け持つモジュールとは別に, 構文木周辺のデータ構造は AST モジュールとして独立している. Parse からのコールバックに応じてSema が AST モジュールのデータ構造(型注釈つき構文木)を構築, CodeGen はそれを受け取って解釈する.
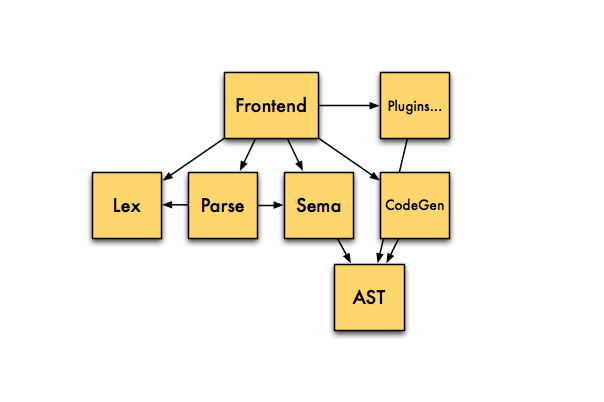
Frontend と Plugin
Lex, Parse, Sema, CodeGen といったモジュールを協調させるのは Frontend の仕事. Frontend にはコンパイラの各フェーズをフックする FrontendAction, ASTFrontendAction など一連の抽象クラスがあり, これらクラスを継承してコンパイラのフェーズ間に処理を差し込む. たとえば AST の構築後にコード生成を差し込むためにこのクラスを使っている.
// include/clang/Frontend/FrontendAction.h
class FrontendAction {
...
virtual ASTConsumer *CreateASTConsumer(CompilerInstance &CI,
llvm::StringRef InFile) = 0;
...
};
// include/clang/AST/ASTConsumer.h
// FrontendAction の実装から Clang に与えるべき AST トラバース用のコールバック.
class ASTConsumer {
virtual void HandleTopLevelDecl(DeclGroupRef D);
virtual void HandleTranslationUnit(ASTContext &Ctx) {}
virtual void HandleVTable(CXXRecordDecl *RD, bool DefinitionRequired) {}
};
Codegen モジュールは ASTFrontendAction のサブクラスとして CodeGenAction クラスを定義している. Fix-It 機能 (Eclise の Ctrl-1 みたいなやつ) も FrontendAction 経由で 実装されているようす. そしてコード補完も同じように実装する...のが自然だと思うよね?
ところがそうなっていない不思議が今日の主たる関心事です.
文字列をつかったコード補完の出力
コード補完候補の取得機能はライブラリとしての Clang がインターフェイス(抽象クラス)経由のコールバックとして提供し, Clang を呼び出すアプリケーションはその抽象クラスを実装して結果を受け取る.
// include/clang/Sema/CodeCompleteConsumer.h
class CodeCompleteConsumer { // 件の抽象クラス
....
virtual void ProcessCodeCompleteResults(Sema &S,
CodeCompletionContext Context,
CodeCompletionResult *Results,
unsigned NumResults) { }
....
virtual void ProcessOverloadCandidates(Sema &S, unsigned CurrentArg,
OverloadCandidate *Candidates,
unsigned NumCandidates) { }
....
};
Clang のコードの中では, コマンドライン "clang -code-completion-at" で呼び出す 文字列ベースのコード補完表示がこのインターフェイスを実装している.
// include/clang/Sema/CodeCompleteConsumer.h
/// \brief A simple code-completion consumer that prints the results it
/// receives in a simple format.
class PrintingCodeCompleteConsumer : public CodeCompleteConsumer {
...
/// \brief Create a new printing code-completion consumer that prints its
/// results to the given raw output stream.
PrintingCodeCompleteConsumer(bool IncludeMacros, bool IncludeCodePatterns,
bool IncludeGlobals,
llvm::raw_ostream &OS)
: CodeCompleteConsumer(IncludeMacros, IncludeCodePatterns, IncludeGlobals,
false), OS(OS) {}
...
};
// lib/Sema/CodeCompleteConsumer.cpp
PrintingCodeCompleteConsumer::ProcessCodeCompleteResults(Sema &SemaRef,
CodeCompletionContext Context,
CodeCompletionResult *Results,
unsigned NumResults) {
std::stable_sort(Results, Results + NumResults);
// Print the results.
for (unsigned I = 0; I != NumResults; ++I) {
OS << "COMPLETION: ";
switch (Results[I].Kind) {
case CodeCompletionResult::RK_Declaration:
OS << Results[I].Declaration;
....
}
....
}
引数に渡ってきた補完候補のリスト Results オブジェクトを整形して コンストラクタで預かっておいた ostream に書き込む. もちろん標準出力の文字列をインターフェイスにするのは Emacs など年寄ツール相手の話. Xcode なんかは IDE 専用にこの API を実装しているのだろう.
候補の列挙
この ProcessCodeCompleteResults() は HandleCodeCompleteResults() を経由して Sema の中のあちこちから呼び出される. たとえば "using namespace" と書いたあとの補完はこんなかんじ:
// lib/Sema/SemaCodeComplete.cpp
void Sema::CodeCompleteUsingDirective(Scope *S) {
if (!CodeCompleter)
return;
// After "using namespace", we expect to see a namespace name or namespace
// alias.
ResultBuilder Results(*this, CodeCompleter->getAllocator(),
CodeCompletionContext::CCC_Namespace,
&ResultBuilder::IsNamespaceOrAlias);
// スコープに紐付く名前空間のリストを集め Results 変数に補完候補として書き込み,
Results.EnterNewScope();
CodeCompletionDeclConsumer Consumer(Results, CurContext);
LookupVisibleDecls(S, LookupOrdinaryName, Consumer,
CodeCompleter->includeGlobals());
Results.ExitScope();
// 登録されている通知用インターフェイス CodeCompleteConsumer にそれを伝える.
// CodeCompleter が CodeCompleteConsumer のインスタンス.
HandleCodeCompleteResults(this, CodeCompleter,
CodeCompletionContext::CCC_Namespace,
Results.data(),Results.size());
}
Sema クラスの中には HandleCodeCompleteResults() の呼び出しが 40 箇所以上ある.
先にちょっと説明したとおり, Sema モジュール (というか Sema クラス) は Parse モジュールから呼ばれて意味解析(=構文木相当のデータ構造の構築)を担う. コード補完にも似たような役割分担がある: Parser クラスが 先の Sema::CodeCompleteUsingDirective() をよびだし, Sema は候補リストを調べあげる.
具体的にどこから呼ばれるのか Parser クラスを眺めてみよう.
// lib/Parse/ParseDeclCXX.cpp
Decl *Parser::ParseUsingDirective(unsigned Context,
SourceLocation UsingLoc,
SourceLocation &DeclEnd,
ParsedAttributes &attrs) {
assert(Tok.is(tok::kw_namespace) && "Not 'namespace' token");
// Eat 'namespace'.
SourceLocation NamespcLoc = ConsumeToken();
if (Tok.is(tok::code_completion)) {
// Actions メンバ変数は Sema のインスタンス.
Actions.CodeCompleteUsingDirective(getCurScope());
ConsumeCodeCompletionToken();
}
CXXScopeSpec SS;
.... のこりの処理が続く...
}
コード補完のタイミングを知らせる特別な字句が表われたら, すかさず Sema に知らせている. つまり Parser は次々と字句(Token)を処理しながら 補完の必要な場所(=テキストエディタの中でカーソルのある場所) を示す tok::code_completion が現れるのを待ち, そのタイミングで Sema にコード補完を求めるというわけ.
Parser クラスのコードには Sema::CodeCompleteXx() の呼び出しがおよそ 80 箇所ある. あちこちいじる羽目になってるけれど, 新しい字句を pull する時はいつでも tok::code_completion が現れうる. 仕方ない.
Parser は補完発生箇所に応じて必要な情報を Sema に渡す. Sema はその情報と意味解析の状態 (スコープやら作りかけの AST やら)を参照して 補完候補を列挙し, Consumer に伝える. たしかにこの作り方だと Parser がくまなくコード補完に備えなければいけない. プラグインにはできないかも... Sema のクラスはわけていい気がするけど, 大クラス主義の Clang に期待はできない.
補完する場所はどこ?
それにしても tok::code_completion には驚いた. 字句ストリームに補完箇所の情報がやってくる. どうやら Lex モジュールもこの仕事に加担しているとみてよさそうだ.
実際, Frontend の一部として一連のオブジェクトを保持する CompilerInstance クラスでは, コード補完の要求箇所を Lex モジュールの Preprocessor にセットする. (Preprocessor というとマクロの展開くらいしかしなそうな響きだけれど, 実際には Lex モジュールの Facade がこう名乗っている.)
// lib/Frontend/CompilerInstance.cpp
static bool EnableCodeCompletion(Preprocessor &PP,
const std::string &Filename,
unsigned Line,
unsigned Column) {
// Tell the source manager to chop off the given file at a specific
// line and column.
const FileEntry *Entry = PP.getFileManager().getFile(Filename);
....
PP.SetCodeCompletionPoint(Entry, Line, Column);
return false;
}
中では何をしているのか...
// lib/Lex/Preprocessor.cpp
bool Preprocessor::SetCodeCompletionPoint(const FileEntry *File,
unsigned TruncateAtLine,
unsigned TruncateAtColumn) {
...
const MemoryBuffer *Buffer = SourceMgr.getMemoryBufferForFile(File, &Invalid);
...
// Find the byte position of the truncation point.
const char *Position = Buffer->getBufferStart();
for (unsigned Line = 1; Line < TruncateAtLine; ++Line) {
// Position を該当箇所まで進める
}
Position += TruncateAtColumn - 1;
// Truncate the buffer.
if (Position < Buffer->getBufferEnd()) {
// バッファの先頭から補完箇所までのソースを切り出し,
llvm::StringRef Data(Buffer->getBufferStart(),
Position-Buffer->getBufferStart());
// 切り出したソースでオリジナルのソースを上書きする
MemoryBuffer *TruncatedBuffer
= MemoryBuffer::getMemBufferCopy(Data, Buffer->getBufferIdentifier());
SourceMgr.overrideFileContents(File, TruncatedBuffer);
}
return false;
}
驚くことにコード補完モードで動く Clang は補完箇所以降のテキストをパース前に切り捨てていた! たしかに逐次処理の最中に補完候補を求めるなら該当箇所以降で何が起きても困らない. ファイル終端を補完トークンの目印にすることだってできるだろう.
確認してみると, 新しい Token オブジェクトを要求する API Preprocessor::Lex() から呼ばれる Lexer::LexEndOfFile() では, たしかに tok::code_completion がセットされている. そして他の箇所ではセットされていない. ここだけ. しかも同じ場所でエラーの握りつぶしを指示している (setsuppressalldiagnostics(true)). これはなんつうか, 豪快だな...
// lib/Lex/Lexer.cpp
bool Lexer::LexEndOfFile(Token &Result, const char *CurPtr) {
..
if (PP && PP->isCodeCompletionFile(FileLoc)) {
..
FormTokenWithChars(Result, CurPtr, tok::code_completion);
..
// Only do the eof -> code_completion translation once.
PP->SetCodeCompletionPoint(0, 0, 0);
// Silence any diagnostics that occur once we hit the code-completion point.
PP->getDiagnostics().setSuppressAllDiagnostics(true);
return true;
}
.. // 本来の処理へすすむ
}
なお一部 Lex モジュール自ら CodeCompletionHandler を呼び出すケースもある. たとえばマクロ名の補完は字句解析の領分だから, Lex は Parse を通さず自らアプリケーションに通知を送る.
性能
それにしてもほんとにインデクスみたいな前処理がなくても平気なんだろうか? 実際のコードで試す...のはコマンドラインの引数を揃えるのが大変そうだから, 簡単なコードを書いて試してみたい:
#include <string>
#include <set>
#include <map>
#include <list>
#include <vector>
#include <algorithm>
#include <iostream>
#include <deque>
#include <stack>
int main()
{
std::vector<int> iv;
std::set<int> is;
std::map<int, int> im;
std::string str;
std::cout << "Hello";
str.
}
実行: (二年くらい前の MacBook です.)
omo$ brew install llvm --with-clang omo$ time /usr/local/bin/clang -cc1 -code-completion-at codecomp.cpp:19:7 codecomp.cpp > /dev/null real 0m0.249s user 0m0.212s sys 0m0.024s # 以下は普通のコンパイル. コードはビルドを通す都合でちょっと直した. omo$ time clang -c codecomp.cpp real 0m0.391s user 0m0.347s sys 0m0.037s
普通にコンパイルする時間の 6 割ちょっと. Clang のページにある 性能の解説記事 によると コンパイル時間のうちコード生成以前にかかる時間は 3-4 割. ちょっと遅いけどだいたいの辻褄はあっている. 数字を云々いうにはコードが短過ぎる気もするけど, パース時間の大半は include したヘッダファイルに費されているだろうから問題なかろう.
テンプレートまみれのやんちゃなコードでもない限り ファイル単位のコンパイルには 1 秒もかからない. つまりコード補完への反応時間は数百ミリ秒. 超高速ではないけれど, まあ許せる範囲に思える. Xcode にインテグレートされればプロセス起動やファイル読み込みはじめ 色々とショートカットして速くできるだろうしね.
どうしてこうなった?
振り返ると, Clang のコード補完は
- Lex は補完する場所でコードをぶったぎり
- その場所までパースをすすめ
- 終端に着いたら字句ストリームを通じて Parse へコード補完を要求し
- Parse は更に Sema に補完を求め,
- Sema は求めに応じて候補リストをつくって専用の Consumer に通知し
- Consumer はそのリストを煮るなり焼くなりする
という複数モジュール横断な一大事業だった.
一方私が想像していたのはこんな方法だった: 普通に構文木を作る. そしてプラグインの中で補完位置から構文木上の該当箇所を探しだし, 候補を列挙する.
でもコードを眺めてから改めて考えると, 構文木から補完候補の場所をさがしだし, 必要な文脈を組み立てるのは簡単でない気がしてくる. C++ の複雑さを反映し入り組んだ構文木はトラバースをするだけでも一苦労. ぶったぎられたファイルのせいで構造も中途半端かもしれない. そもそも構文木に必要な情報は残っているのだろうか? Eclipse は実際に構文木主体のアプローチをとっているけれど, あれはリファクタリングにも耐える強力な基盤あっての大技なのでは?
Clang のアプローチはどうか. たしかに補完支援のコードをあちこち埋め込む必要があるものの, 要変更な箇所は機械的に網羅できる: つまり Lexer はファイル終端に局所化されているし, Parser では字句取得の直後という明快な基準がある. 仕組みはわかりやすい. しかもそこそこ速い. 乱暴だが妥当な方法に思えなくもない.
一方でたとえば gcc がこうした変更を(少なくとも Clang 以前に)許す/許したろうか. plugin にしろと門前払いされる気がする. クールな GUI のためには多少のひどいコードも辞さない Clang スポンサー企業の性格が, こうした大胆不敵な実装を助けたと個人的には思う.
このさきの見所
依存関係の解決がファイルに閉じている C/C++ の性格とコード補完の局所性, そしてコンパイラ自体の速度. これらの特徴をいかした Clang のコード補完は, ハックとしてはかなりの優れものだった.
一方大抵の IDE は(精度はさておき)コード補完くらい 10 年以上前からできている. 現代的な IDE にはコード補完だけじゃなくリファクタリングもできてほしい. Clang が C++ のリファクタリングを実装するとして, このコード補完が土台になるか. どうもそうは思えない.
Clang と Xcode がどうやってリファクタリングを実現するのか - Eclipse や VisualStudio のように編集環境と統合された構文木とデータベースを改めて実装するのか, このコード補完のように新たなハックを編み出すのか, 楽しみなような怖いような心地でございます. あらあらかしこ.